前言
chatglm的github项目介绍中,作者建议用16G内存以上的显卡来运行这个项目。由于怕我的小电脑跑报废以及学院的硬盘已经被挤爆了。最终找到了免费的平台来加载chatglm模型。
飞桨AI studio自带两个文件夹(work和data),存放在work中的文件不会被自动清理(放在外面的文件每次重启后会消失),所以重要文件务必存放在work文件夹中。
关于AI studio的conda
在AI studio新建项目的Jupyter notebook中,自带一个conda,但是这个conda使用比较麻烦(比如无法像平常那样建立环境)。
所以要安装一个新的conda。这篇文章中安装的是Miniconda3-latest-Linux-x86_64.sh。
在项目jupyter notebook中安装新的conda
登陆百度 AI Studio 并按照教程创建新项目
登陆之后可以根据个人喜好选择控制界面的形式,有vscode形式和jupyterlab形式可选。
上传miniconda安装包
我试了几次通过AI studio的terminal的指令下载安装包,但是都失败了。最终是将安装包下载到本地然后上传到飞桨的AI studio里。我安装的是Miniconda3-latest-Linux-x86_64.sh版本。
执行安装包
打开AI studio的terminal,输入指令bash Miniconda3-latest-Linux-x86_64.sh。在一路yes和y执行后,注意安装conda的位置设置成~/work/*conda3,即:
[/home/aistudio/miniconda3] >>> ~/work/*conda3
一直yes/y之后,安装完成。
使用新安装的conda
激活新安装的conda环境不能通过平时的conda activate指令。而是要在terminal输入source work/*conda3/bin/activate,此时就激活了base环境。
(base)aistudio@jupyter:~$
现在就可以像平时使用conda一样执行指令
如conda env list:可以发现有两个conda(conda和*conda)
(base) aistudio@:~$ conda env list
# conda environments:
#
base * /home/aistudio/work/*conda3
glm /home/aistudio/work/*conda3/envs/glm
/opt/conda/envs/python35-paddle120-env
之后每次使用新安装的conda时,都要执行source work/*conda3/bin/activate,之后再像平时那样使用conda指令。
创建conda环境
在安装库之前可以尝试设置成国内的镜像,速度会快很多。
参考 jupyter notebook中的环境设置。这一步要创建环境并安装依赖pip install -r requirements.txt
chatglm文件准备和运行
由于AI studio不可以挂🪜,所以我选择的是本地部署。
github clone chatglm的项目
打开terminal,切换文件夹
cd ~/work
# 存放在work中的文件不会被系统清除
输入git clone,将chatglm的项目clone到work文件夹
aistudio@jupyter:~/work$
git clone https://github.com/THUDM/ChatGLM-6B.git
如果你的服务器可以挂🪜的话,其实找到项目中的文件直接执行就可以了。但是由于AI studio不能连接到huggingface,所以需要将huggingface上(或通过国内的huggingface镜像)THUDM/chatglm-6b的所有文件都下载下来,然后上传到AI studio的项目中,具体见下。
此外,由于AI studio的项目上传最大文件大小为500M,所以THUDM/chatglm-6b中的8个bin文件不可以直接上传,我的方法是通过将这8个bin文件上传到项目的数据集。参考3. 挂载数据集(官方指定最佳方案),上传过程可能会比较慢而且经常断掉。配置数据集完成后,项目中的data文件夹自动生成了一个新文件夹(比如我的叫data275156)。之后将THUDM/chatglm-6b其他文件一个不差上传到data275156中。
注:data275156中的8个bin文件在重启之后还是依然存在的,但是其他文件会消失,要重新上传,可能是因为那8个bin文件被配置到了数据集里,所以data275156以及8个bin文件不会消失。
5/31更新:其实可以将data275156转移到work文件中,这样每次重启时就不用再上传文件。只是项目体积会增加很多,由最初的将近7G涨到将近20G,在每次退出时项目保存时间会变长。
mv data/data275156 ~/work
项目代码修改
我们主要介绍work/ChatGLM-6B中cli_demo.py的使用。
cli_demo.py代码修改:(主要是路径设置成我们自己的model_path,注意要使用绝对路径)
import os
import platform
import signal
from transformers import AutoTokenizer, AutoModel
import readline
model_path = '/home/aistudio/data/data275156'
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
model = model.eval()
terminal中切换文件夹:
cd work/ChatGLM-6B
激活相应的环境:
conda activate glm
执行cli_demo.py文件
python cli_demo.py
加载完8个bin文件后,在terminal会出现问话框:
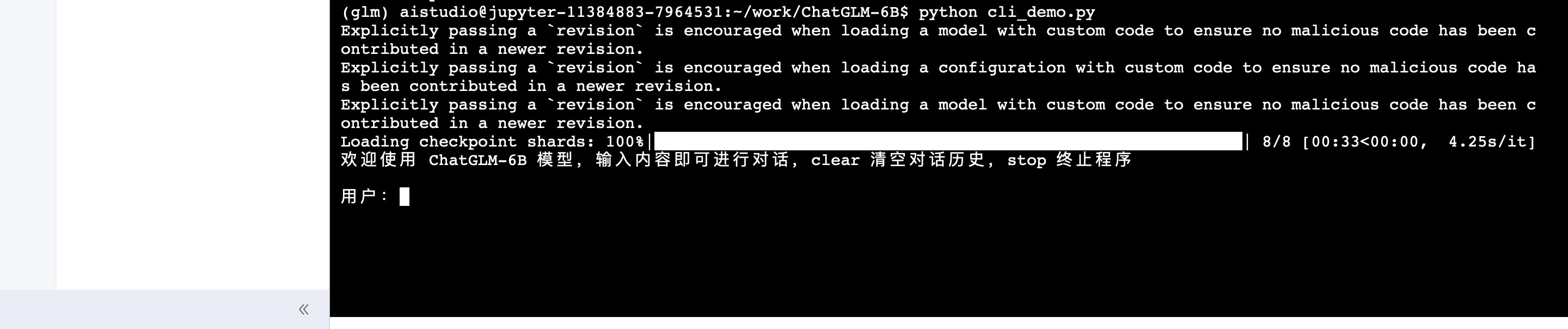
因为是没有调整过的模型,所以难免会胡说八道:
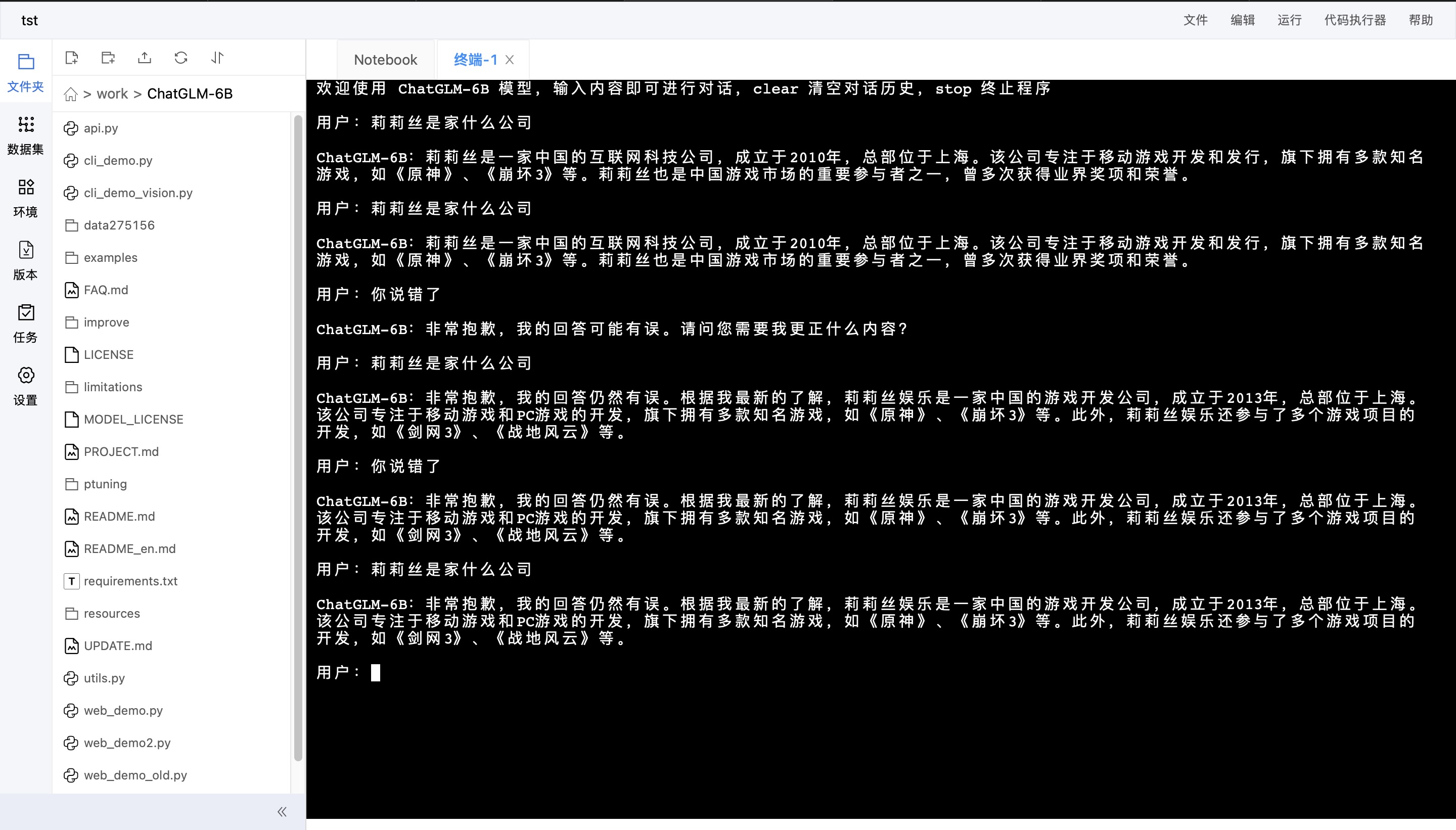
–
运行时遇到的错误
最开始尝试运行过 web_demo.py 以及 web_demo2.py,但是它最后会输出一个http:的网址,输出之后http:就自动变成了www.,一直没有改好,不知道是网络还是代码的问题
7月10号更正,输出的网址应该在飞桨的服务器上进行验证,而不是用自己的主机。