前言
在加载了一个胡说八道的chatglm模型后,下一步的工作是优化它的输出。这里通过RAG的流程,将本地的文本库作为llm的参考,优化其输出。
本项目使用langchian框架,实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。(刚刚做到提示词,目前处在一个比较尴尬的地步,显卡和🪜不能同时具备。)
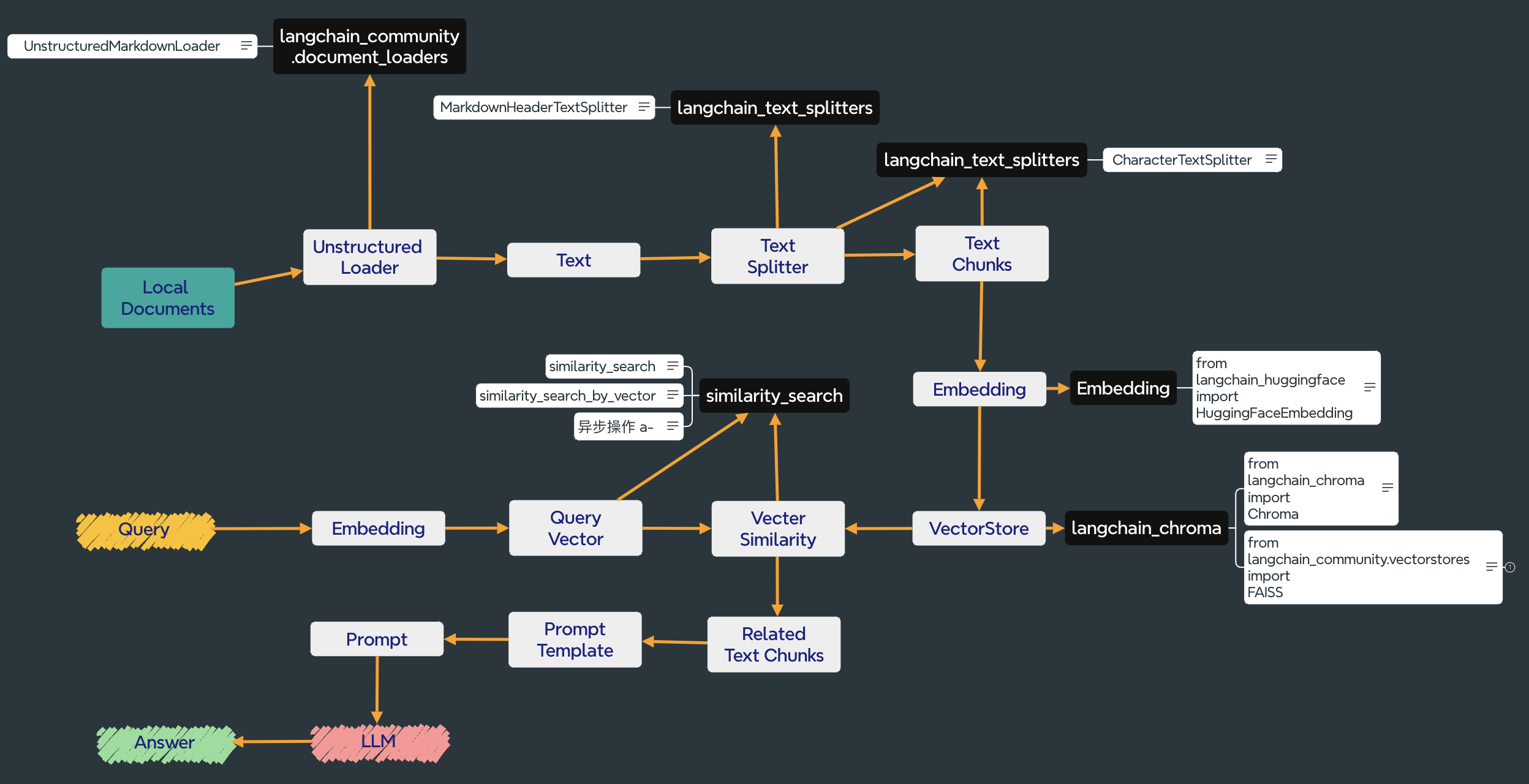
文档上传及切分
Unstructured Loader
我这里上传的是markdown格式的文件,langchain支持多种格式的文件上传,也可以直接上传文件夹。
from langchain_community.document_loaders import UnstructuredMarkdownLoader
markdown_path = '/path'
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
for i in data[0]: # 查看格式
print(i)
('page_content', 'layout: post\ntitle: 利用免费平台加载chatglm\nsubtitle: 飞桨AI studio简介以及chatglm的')
('metadata', {'source': '/Users/klaus_d./Desktop/chatglm.md'})
('type', 'Document')
Text Splitter
文档上传之后,进行分割
以下为一个例子:
from langchain_text_splitters import MarkdownHeaderTextSplitter
# 此工具可以根据文档的标题对文档进行切分
markdown_path = 'md = # Foo\n\n ## Bar\n\nHi this is Jim \nHi this is Joe\n\n ## Baz\n\n Hi this is Molly'
headers_to_split_on = [("#", "Header 1"), ("##", "Header 2"), ("###", "Header 3"),]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_path)
len(md_header_splits) #根据要求被分成了3份
for i in md_header_splits[2]: # 打印分割后文档的第3块输出
print(i)
('page_content', 'Hi this is Molly')
('metadata', {'Header 2': 'Baz'})
('type', 'Document')
分割文档的同时,还可以指定文档的长度,即text chunks。所以text chunks并不需要一个专用的包。
Text Chunks
from langchain_text_splitters import CharacterTextSplitter
# 此工具可将文档按字符分割
with open('markdown_path') as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=300, # 设置每段分割的长度
chunk_overlap=0, # 设置两个分割段落的重叠长度
length_function=len,
is_separator_regex=False)
texts = text_splitter.create_documents([state_of_the_union])
for i in texts[:3]:
print(i.page_content)
len(text_splitter.split_text(state_of_the_union)) # 文档被分割成15段
Created a chunk of size 345, which is longer than the specified 300
Created a chunk of size 345, which is longer than the specified 300
Created a chunk of size 345, which is longer than the specified 300
Created a chunk of size 345, which is longer than the specified 300
227
245
270
文档编码及存储
Embedding
文本转化为向量,这里用的huggingface embedding的all-mpnet-base-v2模型,即默认模型。
from langchain_huggingface import HuggingFaceEmbeddings
embeddings_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2", show_progress=True)
text_to_embedding = [i.page_content for i in texts]
# embed_decuments 接受 list[string] 字符串列表,要对多句话embedding时使用。
embeddings = embeddings_model.embed_documents(text_to_embedding)
# embed_query 接受一个字符串,对一句话 embedding 时使用。
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
查看此embedding 模型的参数,help(embeddings_model)
HuggingFaceEmbeddings(*, client: Any = None,
model_name: str = 'sentence-transformers/all-mpnet-base-v2',
cache_folder: Optional[str] = None,
model_kwargs: Dict[str, Any] = None,
encode_kwargs: Dict[str, Any] = None,
multi_process: bool = False,
show_progress: bool = False) -> None)
VectorStore
这里展示Chroma和FAISS向量存储库
Chroma:
from langchain_chroma import Chroma
db = Chroma.from_documents(texts, embeddings_model)
FAISS:
from langchain_community.vectorstores import FAISS
vectorstore = FAISS.from_documents(texts, embeddings_model)
from_documents接收两个参数,texts是分割好的数据,格式为documents。另一个参数为embeddings_model
help(FAISS.from_documents)
Help on method from\_documents in module langchain_core.vectorstores:
from_documents(documents: 'List[Document]', embedding: 'Embeddings', **kwargs: 'Any') -> 'VST' method of abc.ABCMeta instance
Return VectorStore initialized from documents and embeddings.
Vecter Similarity
比较query向量和vector store中文本向量的相似度,返回文本。
- 当输入query为文本时:
query = "chatglm装在哪里"
docs = db.similarity_search(query)
# 默认返回4个结果
help(db.similarity_search):
Args:
query (str): Query text to search for.
k (int): Number of results to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
- 当输入query为向量时:
embedding_vector = embeddings_model.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
help(db.similarity_search_by_vector):
Args:
embedding (List[float]): Embedding to look up documents similar to.
k (int): Number of Documents to return. Defaults to 4.
filter (Optional[Dict[str, str]]): Filter by metadata. Defaults to None.
Prompt Template & LLM
Prompt Template
PromptTemplate可以被用来指导模型生成特定类型的回答或执行特定的任务。
PromptTemplate可以单独配合vector store使用,也可以与LLM结合使用,以下为单独配合Vector Stroe使用的示例:
from langchain_core.prompts import PromptTemplate
example_prompt = PromptTemplate.from_template("Question: {question}\n{answer}")
examples = [
{
"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
""",
}
]
print(example_prompt.invoke(examples[0]).to_string()):
Question: Who lived longer, Muhammad Ali or Alan Turing?
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
LLM
chatglm-6b的文件中有一个api.py文件,运行这个文件,即可生成一个本地api,再经过langchain导入这个地址 (实际运行时要修改成http://127.0.0.1:8000) 的chatglm。
python api.py
Explicitly passing a
revisionis encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.Explicitly passing a
revisionis encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.Explicitly passing a
revisionis encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Loading checkpoint shards: 100% ████████████████████████████████████████████████████████████████████ 8/8 [00:31<00:00, 3.90s/it] INFO: Started server process [1468]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
之后运行编辑的api_access.py文件,接入这个端口的chatglm。
api_access.py :
import requests
def chat(prompt, history):
resp = requests.post(
url='http://127.0.0.1:8000',
json={'prompt':prompt, 'history':history},
headers={'Content-Type': 'application/json;chatsrt=utf-8'}
)
return resp.json()['response'], resp.json()['history']
history = []
while True:
response, history = chat(input("Question:"), history)
print("Anwser:", response)
输出answer
在没有进行Prompt之前,模型会输出一个离谱的回答:
(langchain) aistudio@jupyter-11384883-7995100:~/work/ChatGLM-6B$ python api_access.py
Question:莉莉丝是什么公司
Anwser: 莉莉丝是一家中国科技公司,成立于2010年,总部位于北京市。该公司专注于移动游戏开发和发行,其最著名的产品是《原神》。
莉莉丝游戏公司是中国领先的游戏开发和发行公司之一,其游戏作品在全球范围内都取得了一定的成功和口碑。除此之外,莉莉丝还推出了一系列其他移动游戏,如《梦幻模拟战》和《梦幻模拟战F》。
莉莉丝在游戏领域拥有强大的实力和市场地位,其公司也一直致力于推动技术创新和行业发展。
接下来将Prompt和问题一起输入:
Question:我会给你一些提示,然后你来回答莉莉丝是什么公司。提示:莉莉丝游戏,全称上海莉莉丝网络科技有限公司,成立于2013年5月,是中国大陆一家以网络游戏为主的公司,因为开发《小冰冰传奇》(原“刀塔传奇”)而知名。[1]公司总部位于中国上海市。2014年,莉莉丝第一款自研产品《刀塔传奇》(现改名“小冰冰传奇”)正式在App Store上线。2017年9月,莉莉丝第二款自研产品《剑与家园》发布。2017年11月2日,《艾彼》正式上架苹果商店。2018年9月,莉莉丝于海外发布代理发行产品《万国觉醒》。2018年,莉莉丝发布《迷失岛2:时间的灰烬》。2019年4月,莉莉丝自研项目《剑与远征》上线。2020年4月,莉莉丝发布益智解谜类游戏《南瓜先生2:九龙城寨》。
Anwser: 非常感谢您提供的提示!根据您提供的这些信息,我可以得出结论:莉莉丝游戏是一家成立于2013年5月,总部位于中国上海市的网络游戏公司,以开发《小冰冰传奇》这款游戏而知名。公司成立于2013年,之后推出了多款自研和代理产品,其中包括《刀塔传奇》、《剑与家园》、《艾彼》、《万国觉醒》、《迷失岛2:时间的灰烬》、《剑与远征》和《南瓜先生2:九龙城寨》等。公司在游戏领域拥有强大的实力和市场地位。
llm此时会根据Prompt进行回答。
再次提问相同的问题,llm也是保持之前的记忆:
Question:莉莉丝是什么公司
Anwser: 莉莉丝游戏是一家总部位于中国上海市的网络游戏公司,成立于2013年。公司以其开发《小冰冰传奇》这款游戏而知名,并随后推出了多款自研和代理产品,如《刀塔传奇》、《剑与家园》、《艾彼》、《万国觉醒》、《迷失岛2:时间的灰烬》、《剑与远征》和《南瓜先生2:九龙城寨》等。公司在游戏领域拥有强大的实力和市场地位。
同时,api.py的终端下也会记录之前的操作:
INFO: 127.0.0.1:51260 - “POST / HTTP/1.1” 200 OK
[2024-06-06 22:31:11] “, prompt:”莉莉丝是什么公司”, response:”‘莉莉丝是一家中国科技公司,成立于2010年,总部位于北京市。该公司专注于移动游戏开发和发行,其最著名的产品是《原神》。\n\n莉莉丝游戏公司是中国领先的游戏开发和发行公司之一,其游戏作品在全球范围内都取得了一定的成功和口碑。除此之外,莉莉丝还推出了一系列其他移动游戏,如《梦幻模拟战》和《梦幻模拟战F》。\n\n莉莉丝在游戏领域拥有强大的实力和市场地位,其公司也一直致力于推动技术创新和行业发展。’”
INFO: 127.0.0.1:43388 - “POST / HTTP/1.1” 200 OK [2024-06-06 22:34:56] “, prompt:”我会给你一些提示,然后你来回答莉莉丝是什么公司。提示:莉莉丝游戏,全称上海莉莉丝网络科技有限公司,成立于2013年5月,是中国大陆一家以网络游戏为主的公司,因为开发《小冰冰传奇》(原“刀塔传奇”)而知名。[1]公司总部位于中国上海市。2014年,莉莉丝第一款自研产品《刀塔传奇》(现改名“小冰冰传奇”)正式在App Store上线。2017年9月,莉莉丝第二款自研产品《剑与家园》发布。2017年11月2日,《艾彼》正式上架苹果商店。2018年9月,莉莉丝于海外发布代理发行产品《万国觉醒》。2018年,莉莉丝发布《迷失岛2:时间的灰烬》。2019年4月,莉莉丝自研项目《剑与远征》上线。2020年4月,莉莉丝发布益智解谜类游戏《南瓜先生2:九龙城寨》。”, response:”‘非常感谢您提供的提示!根据您提供的这些信息,我可以得出结论:莉莉丝游戏是一家成立于2013年5月,总部位于中国上海市的网络游戏公司,以开发《小冰冰传奇》这款游戏而知名。公司成立于2013年,之后推出了多款自研和代理产品,其中包括《刀塔传奇》、《剑与家园》、《艾彼》、《万国觉醒》、《迷失岛2:时间的灰烬》、《剑与远征》和《南瓜先生2:九龙城寨》等。公司在游戏领域拥有强大的实力和市场地位。’”
INFO: 127.0.0.1:51122 - “POST / HTTP/1.1” 200 OK
[2024-06-06 22:35:20] “, prompt:”莉莉丝是什么公司”, response:”‘莉莉丝游戏是一家总部位于中国上海市的网络游戏公司,成立于2013年。公司以其开发《小冰冰传奇》这款游戏而知名,并随后推出了多款自研和代理产品,如《刀塔传奇》、《剑与家园》、《艾彼》、《万国觉醒》、《迷失岛2:时间的灰烬》、《剑与远征》和《南瓜先生2:九龙城寨》等。公司在游戏领域拥有强大的实力和市场地位。’”
INFO: 127.0.0.1:38118 - “POST / HTTP/1.1” 200 OK
此过程没有配合langchain包使用,因为没有执行成功。而是选择手动输入演示。